快速定位Java堆栈信息的问题
jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息。在生产环境,我们可以通过申请应用管理员的权限,或者通过 http://pesword.proxy.taobao.org/tools/ 来dump出服务器的Java堆栈信息。那么问题来了,一个有问题的应用的Java堆栈信息可能是比较多的,以附件中的stack文件为例,有2W多行, 400多个线程,而且每个线程stack信息也比较复杂,当生产环境出现问题的时候如何以最快的速度定位出可能出现问题的地方呢?
一种方法是“Java堆栈信息中出现最频繁的类或者方法可能性最大”
cat stack | grep 'com.aliyun' | sort | uniq -c | sort -k 1 -nr
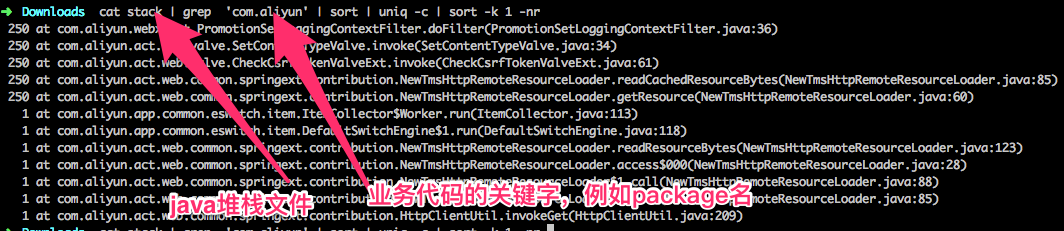
这个例子中,第四行就是我们应用出现问题的地方,有250个线程都block在这个方法上
逐步分解一下这个命令组合
cat stack | grep 'com.aliyun': 在控制台输出stack文件的内容,并通过grep过滤只有自己业务代码的堆栈信息
sort :排序,把相同的字符串放在一起
uniq -c:相同出现的行,合并成一行,并计算重复的次数,输出的结果第一列是出现次数、第二列是内容
sort -k 1 -nr: 按第一列数字从大到小进行排列