转载:MySQL中Cardinality值的介绍
原文:http://www.cnblogs.com/olinux/p/5140615.html
什么是Cardinality
不是所有的查询条件出现的列都需要添加索引。对于什么时候添加B+树索引。一般的经验是,在访问表中很少一部分时使用B+树索引才有意义。对于性别字段、地区字段、类型字段,他们可取值范围很小,称为低选择性。如
SELECT * FROM student WHERE sex='M'
按性别进行查询时,可取值一般只有M、F。因此SQL语句得到的结果可能是该表50%的数据(加入男女比例1:1)这时添加B+树索引是完全没有必要的。相反,如果某个字段的取值范围很广,几乎没有重复,属于高选择性。则此时使用B+树的索引是最合适的。例如对于姓名字段,基本上在一个应用中不允许重名的出现
怎样查看索引是否有高选择性?通过SHOW INDEX结果中的列Cardinality来观察。非常关键,表示所以中不重复记录的预估值,需要注意的是Cardinality是一个预估值,而不是一个准确值基本上用户也不可能得到一个准确的值,在实际应用中,Cardinality/n_row_in_table应尽可能的接近1,如果非常小,那用户需要考虑是否还有必要创建这个索引。故在访问高选择性属性的字段并从表中取出很少一部分数据时,对于字段添加B+树索引是非常有必要的。如
SELECT * FROM member WHERE usernick='David';
表member大约有500W行数据,usernick字段上有一个唯一索引。这是如果查找用户名为David的用户,将得到如下执行计划

可以看到使用了usernick这个索引。这也符合之前提到的高可选择性,即SQL语句取表中较少行的原则
InnoDB存储引擎的Cardinality统计
建立索引的前提是高选择性。这对数据库来说才具有实际意义,那么数据库是怎样统计Cardinality的信息呢?因为MySQL数据库中有各种不同的存储引擎,而每种存储引擎对于B+树索引的实现又各不相同。所以对Cardinality统计时放在存储引擎层进行的
在生成环境中,索引的更新操作可能非常频繁。如果每次索引在发生操作时就对其进行Cardinality统计,那么将会对数据库带来很大的负担。另外需要考虑的是,如果一张表的数据非常大,如一张表有50G的数据,那么统计一次Cardinality信息所需要的时间可能非常长。这样的环境下,是不能接受的。因此,数据库对于Cardinality信息的统计都是通过采样的方法完成
在InnoDB存储引擎中,Cardinality统计信息的更新发生在两个操作中:insert和update。InnoDB存储引擎内部对更新Cardinality信息的策略为:
表中1/16的数据已发生了改变
stat_modified_counter>2000 000 000
第一种策略为自从上次统计Cardinality信息后,表中的1/16的数据已经发生过变化,这是需要更新Cardinality信息
第二种情况考虑的是,如果对表中某一行数据频繁地进行更新操作,这时表中的数据实际并没有增加,实际发生变化的还是这一行数据,则第一种更新策略就无法适用这种情况,故在InnoDB存储引擎内部有一个计数器start_modified_counter,用来表示发生变化的次数,当start_modified_counter>2 000 000 000 时,则同样更新Cardinality信息
接着考虑InnoDB存储引擎内部是怎样进行Cardinality信息统计和更新操作呢?同样是通过采样的方法。默认的InnoDB存储引擎对8个叶子节点Leaf Page进行采用。采用过程如下
取得B+树索引中叶子节点的数量,记为A
随机取得B+树索引中的8个叶子节点,统计每个页不同记录的个数,即为P1,P2....P8
通过采样信息给出Cardinality的预估值:Cardinality=(P1+P2+...+P8)*A/8
根据上述的说明可以发现,在InnoDB存储引擎中,Cardinality值通过对8个叶子节点预估而得的。而不是一个实际精确的值。再者,每次对Cardinality值的统计,都是通过随机取8个叶子节点得到的,这同时有暗示了另外一个Cardinality现象,即每次得到的Cardinality值可能不同的,如
SHOW INDEX FROM OrderDetails
上述SQL语句会触发MySQL数据库对于Cardinality值的统计,第一次运行得到的结果如图5-20

在上述测试过程中,并没有通过INSERT、UPDATE这类的操作来改变OrderDetails中的内容,但是当第二次运行SHOW INDEX FROM OrderDetails语句是,发生了变化,如图5-21

可以看到,当第二次运行SHOW INDEX FROM OrderDetails语句时,表OrderDetails索引中的Cardinality值发生了变化,虽然表OrderDetails本身并没有发生任何变化,但是由于Cardinality是随机取8个叶子节点进行分析,所以即使表没有发生变化,用户观察到索引Cardinality值还是会发生变化,这本身不是Bug,而是随机采样而导致的结果
当然,有一种情况可以使得用户每次观察到的索引Cardinality值是一样的。那就是表足够小,表的叶子节点树小于或者等于8个。这时即使随机采样,也总是会采取倒这些页,因此每次得到的Cardinality值是相同的
在InnoDB1.2版本之前,可以通过innodb_stats_sample_pages用来设置统计Cardinality时每次采样页的数量,默认为8.同时,参数innodb_stats_method用来判断如何对待索引中出现NULL值记录。该参数默认值为nulls_equal,表示将NULL值记录为相等的记录。其有效值还nulls_unequal,nulls_ignored,分别表示将NULL值记录视为不同的记录和忽略NULL值记录。例如某夜中索引记录为NULL、NULL、1、2、2、3、3、3,在参数innodb_stats_method默认设置下,该页的Cardinality为4;若参数innodb_stats_method为nulls_unequal,则该页的Cardinality为5,若参数innodb_stats_method为nulls_ignored,则Cardinality值为3
当执行ANALYZE TABLE、SHOW TABLE STATUS、SHOW INDEX 以及访问INFORMATION_SCHEMA架构下的表TABLES和STATISTICS时会导致InnoDB存储引擎会重新计算索引Cardinality值,若表中的数据量非常大,并且表中存在多个辅助索引时,执行上述操作可能会非常慢,虽然用户可能并不希望去更新Cardinality值
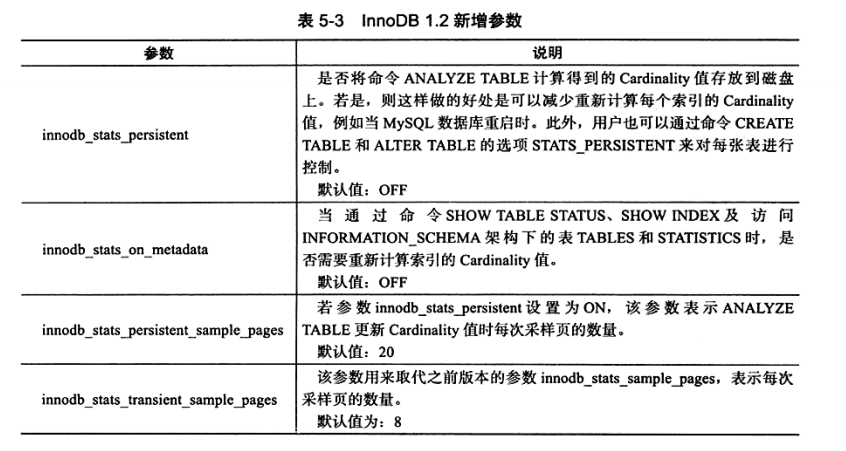
InnoDB1.2版本提供了更多参数对Cardinality进行设置。如表